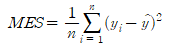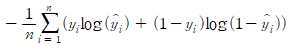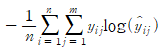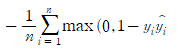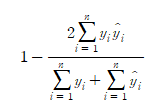데이터 전처리는 데이터 분석의 첫 번째 단계로, 데이터를 수집, 정제 및 변환하여 분석에 적합한 형태로 만드는 과정입니다. 이 단계에서는 데이터의 결측값, 이상값, 중복값 등을 처리하고, 데이터 형식을 일치시키는 등의 작업이 필요합니다.
아래 내용은 chatGPT의 도움을 받아 작성하였습니다.
1) 데이터 수집:
데이터 전처리의 첫 번째 단계는 데이터를 수집하는 것입니다. 데이터는 다양한 소스에서 수집될 수 있으며, 주로 파일, 데이터베이스, 웹사이트, 센서 등에서 수집됩니다. 데이터를 수집할 때는 데이터의 크기, 형식, 속성 등을 고려하여 적절한 방법을 선택해야 합니다.
데이터 수집 방법:
어떤 데이터를 수집할 때 어떤 방식으로 수집하는 것이 적절한지에 대한 문제입니다. 예를 들어, 소셜미디어 데이터를 수집할 때 어떤 API를 사용하는 것이 좋은지, 스크래핑(scraping) 기술을 사용하는 것이 적절한지 등을 묻는 문제가 출제될 수 있습니다.
데이터 소스:
데이터를 수집할 때 어떤 소스를 사용해야 하는지에 대한 문제입니다. 예를 들어, 웹사이트에서 데이터를 수집할 때, 어떤 라이브러리를 사용해야 하는지, 어떤 프로토콜을 사용해야 하는지 등을 묻는 문제가 출제될 수 있습니다.
데이터 수집 기간:
데이터 수집 기간에 대한 문제입니다. 예를 들어, 어떤 기간의 데이터를 수집할 때 몇일 이전부터 몇일 이후까지의 데이터를 수집해야 하는지 등을 묻는 문제가 출제될 수 있습니다.
데이터 크기:
수집한 데이터의 크기와 관련된 문제입니다. 예를 들어, 어떤 데이터를 수집할 때 어느정도의 크기의 데이터를 수집해야 하는지, 수집한 데이터의 용량을 줄이기 위해 어떤 방식을 사용해야 하는지 등을 묻는 문제가 출제될 수 있습니다.
2) 데이터 정제:
데이터 정제는 데이터를 다듬어주는 과정으로, 결측값, 이상값, 중복값 등을 처리하는 작업입니다. 결측값은 데이터가 누락된 경우로, 해당 값을 대체하거나 삭제하는 방법을 사용합니다. 이상값은 데이터가 이상하게 기록된 경우로, 대부분 실수에 의한 것이며, 이상값을 검출하고 대체하거나 삭제하는 작업을 수행합니다. 중복값은 데이터가 중복된 경우로, 중복을 제거하는 방법을 사용합니다.
결측값 처리:
결측값을 처리하는 방법에 대한 문제입니다. 예를 들어, 결측값을 삭제하거나 다른 값으로 대체하는 방법 등을 묻는 문제가 출제될 수 있습니다.
이상값 처리:
이상값을 처리하는 방법에 대한 문제입니다. 예를 들어, 이상값을 검출하고 대체하거나 삭제하는 방법 등을 묻는 문제가 출제될 수 있습니다.
중복값 처리:
중복값을 처리하는 방법에 대한 문제입니다. 예를 들어, 중복된 데이터를 제거하거나 중복을 허용하지 않는 방법 등을 묻는 문제가 출제될 수 있습니다.
데이터 형식 일치화:
데이터 형식을 일치시키는 방법에 대한 문제입니다. 예를 들어, 텍스트 데이터를 수치형 데이터로 변환하는 방법이나 범주형 데이터를 더미 변수로 변환하는 방법 등을 묻는 문제가 출제될 수 있습니다.
스케일링:
데이터 스케일링을 수행하는 방법에 대한 문제입니다. 예를 들어, 표준화(Standardization)나 정규화(Normalization) 등의 방법을 묻는 문제가 출제될 수 있습니다.
3) 데이터 변환:
데이터 변환은 데이터의 형식을 일치시켜주는 작업입니다. 데이터 형식은 수치형, 범주형, 텍스트형 등 다양한 형태로 존재합니다. 이러한 형식을 일치시켜주지 않으면 데이터 분석에 어려움이 생길 수 있습니다. 예를 들어, 텍스트 데이터를 수치 데이터로 변환하거나, 범주형 데이터를 더미 변수(dummy variable)로 변환하는 등의 작업을 수행합니다.
데이터 형식 변환:
데이터 형식을 변환하는 방법에 대한 문제입니다. 예를 들어, 텍스트 데이터를 수치형 데이터로 변환하거나, 범주형 데이터를 더미 변수(dummy variable)로 변환하는 방법 등을 묻는 문제가 출제될 수 있습니다.
데이터 범위 변환:
데이터의 범위를 변환하는 방법에 대한 문제입니다. 예를 들어, 로그 변환(log transformation) 등의 방법을 사용하여 데이터의 범위를 일치시키는 방법을 묻는 문제가 출제될 수 있습니다.
데이터 스케일링:
데이터 스케일링을 수행하는 방법에 대한 문제입니다. 예를 들어, 표준화(Standardization)나 정규화(Normalization) 등의 방법을 묻는 문제가 출제될 수 있습니다.
데이터 합치기:
여러 개의 데이터를 하나로 합치는 방법에 대한 문제입니다. 예를 들어, 조인(join) 기능을 사용하거나 피벗(pivot) 기능을 사용하는 등의 방법을 묻는 문제가 출제될 수 있습니다.
데이터 샘플링:
데이터 샘플링을 수행하는 방법에 대한 문제입니다. 예를 들어, 무작위 샘플링, 계층 샘플링 등의 방법을 묻는 문제가 출제될 수 있습니다.
4) 데이터 스케일링:
데이터 합치기는 여러 개의 데이터를 하나로 합치는 작업입니다. 데이터가 여러 개로 분산되어 있을 경우, 이를 하나로 합치는 것이 분석을 수행하기 용이해집니다. 이를 위해, 조인(join) 기능을 사용하거나 피벗(pivot) 기능을 사용하는 등의 방법이 있습니다.
표준화:
데이터를 표준화하는 방법에 대한 문제입니다. 예를 들어, 평균을 0, 표준편차를 1로 만들어 데이터의 범위를 일치시키는 방법을 묻는 문제가 출제될 수 있습니다.
정규화:
데이터를 정규화하는 방법에 대한 문제입니다. 예를 들어, 데이터를 0과 1 사이의 범위로 변환하여 데이터의 스케일을 일치시키는 방법을 묻는 문제가 출제될 수 있습니다.
최대-최소 스케일링:
데이터의 범위를 최대값과 최소값으로 정해 데이터를 스케일링하는 방법에 대한 문제입니다. 예를 들어, 데이터의 최대값을 1, 최소값을 0으로 만들어 데이터의 범위를 일치시키는 방법을 묻는 문제가 출제될 수 있습니다.
로그 변환:
데이터에 로그 변환을 적용하여 스케일링하는 방법에 대한 문제입니다. 예를 들어, 데이터가 치우쳐져 있을 경우 로그 변환을 적용하여 스케일링하는 방법을 묻는 문제가 출제될 수 있습니다.
5) 데이터 샘플링:
데이터 샘플링은 대용량의 데이터에서 일부 데이터를 추출하는 작업입니다. 이를 통해 분석에 필요한 적절한 크기의 데이터를 확보할 수 있습니다. 데이터 샘플링에는 무작위 샘플링, 계층 샘플링 등의 방법이 있습니다.
무작위 샘플링:
데이터에서 무작위로 샘플을 추출하는 방법에 대한 문제입니다. 예를 들어, 어떤 데이터셋에서 무작위로 100개의 샘플을 추출하는 방법을 묻는 문제가 출제될 수 있습니다.
계층 샘플링:
데이터를 여러 계층으로 나누어 각 계층에서 일정한 비율로 샘플을 추출하는 방법에 대한 문제입니다. 예를 들어, 어떤 데이터셋에서 특정 지역, 연령대, 성별 등으로 나누어 각 계층에서 일정한 비율로 샘플을 추출하는 방법을 묻는 문제가 출제될 수 있습니다.
층화 샘플링:
데이터를 여러 층으로 나누어 각 층에서 동일한 개수의 샘플을 추출하는 방법에 대한 문제입니다. 예를 들어, 어떤 데이터셋에서 동일한 개수의 샘플을 추출하기 위해 데이터를 여러 층으로 나누는 방법을 묻는 문제가 출제될 수 있습니다.
클러스터 샘플링:
데이터를 클러스터로 나누어 각 클러스터에서 샘플을 추출하는 방법에 대한 문제입니다. 예를 들어, 어떤 데이터셋에서 k-means 클러스터링을 수행하고 각 클러스터에서 일정한 비율로 샘플을 추출하는 방법을 묻는 문제가 출제될 수 있습니다.
6) 데이터 저장:
데이터 전처리가 완료되면, 분석에 필요한 형식으로 데이터를 저장하는 작업을 수행합니다. 이를 위해 다양한 형식의 파일로 저장할 수 있습니다. 예를 들어, CSV, Excel, JSON 등의 파일 형식으로 저장하거나 데이터베이스에 저장할 수 있습니다.
데이터베이스:
데이터베이스를 설계하고 운용하는 방법에 대한 문제입니다. 예를 들어, SQL을 사용하여 테이블을 생성하거나 데이터를 삽입하는 방법을 묻는 문제가 출제될 수 있습니다.
NoSQL 데이터베이스:
NoSQL 데이터베이스를 설계하고 운용하는 방법에 대한 문제입니다. 예를 들어, MongoDB에서 데이터를 삽입하고 검색하는 방법을 묻는 문제가 출제될 수 있습니다.
파일 시스템:
파일 시스템을 설계하고 운용하는 방법에 대한 문제입니다. 예를 들어, 리눅스에서 파일 및 디렉토리를 생성하고 관리하는 방법을 묻는 문제가 출제될 수 있습니다.
클라우드 스토리지:
클라우드 스토리지를 이용하여 데이터를 저장하고 관리하는 방법에 대한 문제입니다. 예를 들어, AWS S3에서 데이터를 업로드하거나 다운로드하는 방법을 묻는 문제가 출제될 수 있습니다.
데이터 보안:
데이터를 안전하게 저장하고 관리하는 방법에 대한 문제입니다. 예를 들어, 데이터 암호화, 백업 및 복원, 데이터 무결성 등의 방법을 묻는 문제가 출제될 수 있습니다.
한국에서 빅데이터 전문가가 되기 위한 과정 중 하나로, 빅데이터 전문가 필기시험이 있습니다. 이 시험은 한국데이터산업진흥원(KDATA)에서 주관하며, 빅데이터 분석 기술 및 활용 능력을 갖춘 전문 인력 양성을 목표로 합니다. 빅데이터 전문가 필기시험은 빅데이터 분석 기술과 이론에 대한 이해를 평가하는 시험입니다. 필기시험 합격 후 실기시험을 통해 빅데이터 전문가 자격증을 취득할 수 있습니다.
빅데이터 전문가 필기시험은 다음과 같은 주요 내용을 포함합니다:
빅데이터 이해: 빅데이터의 개념, 특징, 유형, 기술 및 활용 분야에 대한 이해와 관련된 질문이 출제됩니다.
데이터 처리 및 분석: 데이터 처리와 분석을 위한 기본적인 통계 지식, 데이터 전처리, 데이터 마이닝, 기계학습 알고리즘 등에 대한 이해와 관련된 질문이 출제됩니다.
데이터 저장 및 관리: 데이터베이스, 데이터 웨어하우스, NoSQL 등 다양한 데이터 저장 및 관리 기술에 대한 이해와 관련된 질문이 출제됩니다.
빅데이터 환경 구축 및 운영: 하둡, 스파크 등 빅데이터 처리를 위한 플랫폼과 인프라, 클라우드 컴퓨팅, 분산 처리 등의 기술에 대한 이해와 관련된 질문이 출제됩니다.
빅데이터 분석 및 활용: 빅데이터 시각화, 텍스트 마이닝, 소셜 네트워크 분석, 추천 시스템 등 다양한 분석 및 활용 방법에 대한 이해와 관련된 질문이 출제됩니다.
앞으로 데이터분석기사에 대한 포스팅을 꾸준히 이어갈 예정입니다.
2023년 빅데이터 분석기사 시험 일정
올해는 제7회 빅데이터 분석기사에 접수를 해봐야겠네요.
우연히 후배를 통해 알게된 자격증인데 제가 관심있는 분야라 한번 도전해봐야겠습니다.ㅎ
실기는 python의 numpy와 pandas 함수를 잘 사용하면 될 것 같습니다만.. 이것도 예제들도 많이 함께 풀어보고 해야겠습니다.
앙상블 학습 (Ensemble Learning)은 여러 개의 모델을 조합하여 하나의 예측 모델을 만드는 방법으로, 개별 모델보다 높은 정확도와 안정성을 보이는 것이 특징입니다. 이는 일반적으로 머신러닝에서 최적화 문제를 해결하는 데 사용됩니다.
1. 배깅(Bagging)
배깅은 Bootstrap Aggregating의 줄임말로, 동일한 알고리즘을 사용하는 여러 개의 모델을 만들고, 각 모델이 만든 예측 결과를 결합하여 최종 예측을 수행하는 방법입니다. 각 모델은 원래 데이터에서 무작위로 선택된 일부 샘플 데이터를 사용하여 학습됩니다. 이는 과적합을 방지하고 모델의 분산을 줄여 성능을 개선하는 데 도움이 됩니다. 대표적인 알고리즘으로는 랜덤 포레스트 (Random Forest)가 있습니다.
랜덤 포레스트(Random Forest)
랜덤 포레스트는 의사 결정 나무(Decision Tree)를 기본 모델로 사용하는 알고리즘입니다. 여러 개의 의사 결정 나무를 만들어서 학습시키고, 각 나무의 예측 결과를 평균(회귀의 경우) 또는 투표(분류의 경우)를 통해 최종 예측을 결정합니다. 무작위성을 높이기 위해 데이터셋에서 무작위로 특성(feature)을 선택하여 학습시킵니다. 랜덤 포레스트의 학습 과정은 다음과 같습니다.
1) 데이터셋으로부터 부트스트랩 샘플을 추출합니다.
2) 추출된 샘플로부터 무작위로 특성을 선택하여 의사 결정 나무를 학습시킵니다.
3) 위 과정을 사용자가 지정한 트리 개수만큼 반복합니다.
4) 각 트리의 예측 결과를 평균(회귀) 또는 투표(분류)하여 최종 예측을 결정합니다.
배깅 결정 나무(Bagging Decision Trees)
배깅 결정 나무(Bagging Decision Trees)는 결정 나무(Decision Tree)를 기본 모델로 사용하고, 배깅(Bagging) 기법을 적용하여 여러 개의 결정 나무를 학습시키고 그 결과를 집계하는 앙상블 학습 방법입니다. 배깅은 과적합을 방지하고 모델의 분산을 줄이는 효과가 있으며, 병렬적으로 학습이 이루어집니다.
배깅 결정 나무의 학습 과정은 다음과 같습니다.
1) 데이터셋에서 부트스트랩 샘플(Bootstrap samples)을 추출합니다. 부트스트랩 샘플링은 원본 데이터셋에서 중복을 허용하여 무작위로 샘플을 선택하는 과정입니다. 이렇게 추출된 샘플들은 각각의 결정 나무를 학습시키는 데 사용됩니다.
2)각 부트스트랩 샘플에 대해 결정 나무를 학습시킵니다. 이 때, 모든 특성(feature)을 사용하여 학습합니다. 이 과정을 사용자가 지정한 결정 나무의 개수만큼 반복합니다.
3) 각 결정 나무의 예측 결과를 집계하여 최종 예측을 결정합니다. 회귀 문제의 경우 각 나무의 예측 값을 평균하여 최종 결과를 얻고, 분류 문제의 경우 각 나무의 예측 클래스에 대해 투표를 실시하여 가장 많은 투표를 받은 클래스를 최종 결과로 결정합니다.
배깅 결정 나무는 랜덤 포레스트와 비슷한 방식으로 작동하지만, 랜덤 포레스트가 각 결정 나무를 학습할 때 무작위로 특성을 선택하는 반면, 배깅 결정 나무는 모든 특성을 사용하여 학습한다는 점에서 차이가 있습니다. 이로 인해 배깅 결정 나무는 랜덤 포레스트에 비해 다소 덜 무작위하게 작동하며, 랜덤 포레스트에 비해 분산은 높을 수 있지만, 편향은 낮을 수 있습니다.
2. 부스팅 (Boosting)
부스팅(Boosting)은 앙상블 학습의 한 방법으로, 여러 개의 약한 학습기(Weak Learners)를 순차적으로 학습시켜 각 학습기의 예측 오차를 줄이는 방식으로 작동합니다. 약한 학습기란 단독으로 사용했을 때 예측 성능이 낮은 모델을 의미합니다. 부스팅은 이러한 약한 학습기들을 순차적으로 결합하여 전체적인 예측 성능을 향상시키는 기법입니다.
부스팅의 핵심 아이디어는 이전 학습기의 예측 오차를 보완하는 방식으로 새로운 학습기를 학습시키는 것입니다. 각 학습기는 이전 학습기의 오차에 가중치를 더하여 새로운 학습기가 이 오차를 최소화하도록 학습됩니다. 마지막으로, 각 학습기의 예측 결과를 가중치를 고려하여 결합하여 최종 예측을 수행합니다.
대표적인 알고리즘으로는 에이다부스트 (AdaBoost), 그래디언트 부스팅 (Gradient Boosting) 등이 있습니다.
AdaBoost(Adaptive Boosting)와 그래디언트 부스팅(Gradient Boosting)은 두 가지 대표적인 부스팅 알고리즘입니다. 두 알고리즘 모두 약한 학습기들을 순차적으로 결합하여 전체적인 예측 성능을 향상시키는 방법이지만, 각각의 접근 방식에 차이가 있습니다.
AdaBoost(Adaptive Boosting):
AdaBoost는 첫 번째 학습기를 학습시킨 후, 잘못 분류된 데이터 포인트에 높은 가중치를 부여하고 다음 학습기를 학습시킵니다. 이 과정을 반복하면서 각 학습기의 가중치를 업데이트하고, 최종 예측 결과는 각 학습기의 가중치를 고려하여 결합됩니다.
AdaBoost의 학습 과정은 다음과 같습니다.
1) 데이터셋의 모든 관측치에 동일한 가중치를 부여하여 첫 번째 약한 학습기를 학습시킵니다.
2) 첫 번째 약한 학습기의 예측 결과를 바탕으로 오분류된 데이터에 높은 가중치를 부여합니다.
3) 새로 조정된 가중치를 가진 데이터셋을 사용하여 두 번째 약한 학습기를 학습시킵니다.
4) 이 과정을 사용자가 지정한 학습기의 개수만큼 반복합니다.
5) 각 학습기의 가중치를 고려하여 최종 결과를 결합합니다.
AdaBoost는 오분류된 데이터에 집중하여 가중치를 조절하고 약한 학습기를 학습시키는 방식으로 작동합니다. 이로 인해 앙상블 모델의 성능이 향상됩니다. 일반적으로 의사 결정 나무를 약한 학습기로 사용하지만, 다른 모델도 사용 가능합니다.
그래디언트 부스팅(Gradient Boosting):
그래디언트 부스팅은 약한 학습기를 순차적으로 학습시키되, 이전 학습기의 잔차(Residual)를 최소화하는 방향으로 새로운 학습기를 학습시킵니다. 그래디언트 부스팅은 회귀와 분류 문제 모두에 적용할 수 있으며, 손실 함수의 그래디언트(미분 값)를 사용하여 모델을 업데이트합니다. 이로 인해 최적의 학습 경로를 찾아 손실 함수를 최소화할 수 있습니다.
그래디언트 부스팅의 학습 과정은 다음과 같습니다.
1) 첫 번째 약한 학습기를 학습시키고 예측 결과를 계산합니다.
2) 첫 번째 약한 학습기의 예측 결과와 실제 값 사이의 잔차를 계산합니다.
3) 이 잔차를 목표 변수로 삼아 두 번째 약한 학습기를 학습시킵니다.
4) 이 과정을 사용자가 지정한 학습기의 개수만큼 반복합니다.
5) 각 학습기의 예측 결과를 합하여 최e) 각 학습기의 예측 결과를 합하여 최종 결과를 얻습니다.
그래디언트 부스팅은 손실 함수의 그래디언트(미분 값)를 사용하여 모델을 업데이트하고, 최적의 학습 경로를 찾아 손실 함수를 최소화합니다. 이로 인해 그래디언트 부스팅은 높은 성능을 달성할 수 있습니다. 그래디언트 부스팅은 회귀와 분류 문제 모두에 적용할 수 있으며, 의사 결정 나무 등 다양한 약한 학습기를 사용할 수 있습니다.
AdaBoost와 그래디언트 부스팅은 둘 다 부스팅 방식을 사용하는 알고리즘이지만, 가중치 업데이트 방식과 목표 변수 설정 방식에 차이가 있습니다. AdaBoost는 오분류된 데이터에 가중치를 높이고, 그래디언트 부스팅은 이전 학습기의 예측 결과와 실제 값 사이의 잔차를 최소화하는 방향으로 새로운 학습기를 학습시킵니다.
부스팅 알고리즘은 높은 성능을 달성할 수 있지만, 순차적인 학습 방식 때문에 학습 속도가 느리고 병렬화하기 어렵다는 단점이 있습니다. 그러나 최근에는 XGBoost, LightGBM, CatBoost와 같은 효율적인 그래디언트 부스팅 라이브러리가 개발되어 있어, 이러한 문제를 어느 정도 해결할 수 있습니다. 이들 라이브러리는 고급 최적화 기법과 병렬 처리 기능을 사용하여 그래디언트 부스팅의 학습 속도를 크게 개선하였습니다.
3. 스태킹(Stacking)
스태킹(Stacking)은 앙상블 학습의 한 방법으로, 여러 개의 다양한 기본 모델(Base Models)의 예측 결과를 조합하여 새로운 메타 모델(Meta Model)을 학습시키는 기법입니다. 스태킹은 여러 모델의 강점을 결합하여 더 나은 예측 성능을 달성할 수 있습니다.
스태킹의 학습 과정은 다음과 같습니다.
1) 훈련 데이터셋을 두 개의 서브셋(Subsets)으로 나눕니다. 일반적으로 첫 번째 서브셋은 기본 모델을 학습시키는 데 사용되며, 두 번째 서브셋은 메타 모델을 학습시키는 데 사용됩니다.
2) 첫 번째 서브셋을 사용하여 다양한 기본 모델을 학습시킵니다. 이 모델들은 서로 다른 알고리즘을 사용하거나 다른 하이퍼파라미터 설정을 가질 수 있습니다.
3) 학습된 기본 모델들을 사용하여 두 번째 서브셋에 대한 예측을 수행합니다. 이 예측 결과는 메타 모델의 훈련 데이터로 사용됩니다. 기본 모델의 예측 결과를 행렬로 나타내면, 각 열은 각 기본 모델의 예측 결과를 의미하고, 각 행은 각 데이터 포인트에 대한 예측 결과를 의미합니다.
4) 메타 모델을 학습시키기 위해 기본 모델들의 예측 결과를 입력으로 사용하고, 원래의 두 번째 서브셋의 타겟 변수를 출력으로 사용하여 학습시킵니다.
5) 메타 모델은 기본 모델들의 예측 결과를 조합하여 최종 예측을 수행합니다.
스태킹은 다양한 모델의 성능을 활용하여 더 나은 예측 결과를 얻을 수 있다는 장점이 있습니다. 그러나 스태킹의 단점으로는 모델 학습과 예측 과정이 복잡하고 시간이 오래 걸린다는 점이 있습니다. 이는 기본 모델과 메타 모델을 모두 학습시켜야 하기 때문입니다. 또한, 스태킹은 오버피팅(Overfitting)의 위험성이 존재하므로, 교차 검증(Cross-Validation) 같은 기법을 사용하여 모델의 일반화 성능을 확인하고 향상시키는 것이 중요합니다.
스태킹을 사용하는 경우 다음 사항을 고려할 수 있습니다:
기본 모델 선택: 서로 다른 알고리즘을 사용하는 다양한 기본 모델을 선택하여 스태킹에 사용할 수 있습니다. 이를 통해 각 모델의 강점을 조합하여 더 나은 성능을 얻을 수 있습니다. 예를 들어, 선형 회귀, 의사 결정 나무, 랜덤 포레스트, 서포트 벡터 머신 등 다양한 모델을 기본 모델로 사용할 수 있습니다.
메타 모델 선택: 메타 모델은 기본 모델들의 예측 결과를 조합하여 최종 예측을 수행하는 모델입니다. 메타 모델로는 간단한 모델(예: 선형 회귀)부터 복잡한 모델(예: 그래디언트 부스팅)까지 다양한 모델을 사용할 수 있습니다. 메타 모델 선택시 과적합을 피하고, 일반화 성능을 높이는 것이 중요합니다.
교차 검증 사용:스태킹은 기본 모델과 메타 모델을 모두 학습시켜야 하므로, 오버피팅의 위험이 존재합니다. 이를 방지하기 위해 교차 검증을 사용하여 모델의 일반화 성능을 확인하고 향상시킬 수 있습니다.
하이퍼파라미터 최적화:기본 모델과 메타 모델 모두 하이퍼파라미터를 최적화하는 것이 중요합니다. 그리드 탐색(Grid Search), 랜덤 탐색(Random Search), 베이지안 최적화(Bayesian Optimization) 등의 기법을 사용하여 최적의 하이퍼파라미터 조합을 찾을 수 있습니다.
스태킹은 앙상블 학습 기법 중 하나로, 기본 모델과 메타 모델을 적절히 조합하여 높은 성능을 달성할 수 있습니다. 그러나 복잡한 학습 과정과 오버피팅의 위험성으로 인해 신중하게 사용하고 최적화해야 합니다.
import numpy as np
from sklearn.datasets import load_iris
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.ensemble import RandomForestClassifier, BaggingClassifier, AdaBoostClassifier, GradientBoostingClassifier, StackingClassifier
from sklearn.tree import DecisionTreeClassifier
from sklearn.linear_model import LogisticRegression
# 데이터 로드
iris = load_iris()
X, y = iris.data, iris.target
# 데이터를 학습 및 테스트 세트로 분할
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# 랜덤 포레스트
rf = RandomForestClassifier(n_estimators=100, random_state=42)
rf.fit(X_train, y_train)
y_pred_rf = rf.predict(X_test)
print("Random Forest Accuracy:", accuracy_score(y_test, y_pred_rf))
# 배깅 결정 나무
bagging_dt = BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100, random_state=42)
bagging_dt.fit(X_train, y_train)
y_pred_bagging_dt = bagging_dt.predict(X_test)
print("Bagging Decision Tree Accuracy:", accuracy_score(y_test, y_pred_bagging_dt))
# AdaBoost
ada = AdaBoostClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100, random_state=42)
ada.fit(X_train, y_train)
y_pred_ada = ada.predict(X_test)
print("AdaBoost Accuracy:", accuracy_score(y_test, y_pred_ada))
# 그래디언트 부스팅
gb = GradientBoostingClassifier(n_estimators=100, random_state=42)
gb.fit(X_train, y_train)
y_pred_gb = gb.predict(X_test)
print("Gradient Boosting Accuracy:", accuracy_score(y_test, y_pred_gb))
# 스태킹
estimators = [
('rf', RandomForestClassifier(n_estimators=100, random_state=42)),
('bagging_dt', BaggingClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100, random_state=42)),
('ada', AdaBoostClassifier(base_estimator=DecisionTreeClassifier(), n_estimators=100, random_state=42)),
('gb', GradientBoostingClassifier(n_estimators=100, random_state=42))
]
stacking = StackingClassifier(estimators=estimators, final_estimator=LogisticRegression(), cv=5)
stacking.fit(X_train, y_train)
y_pred_stacking = stacking.predict(X_test)
print("Stacking Accuracy:", accuracy_score(y_test, y_pred_stacking))
위 코드에서는 아이리스 데이터셋을 사용하여 각각의 앙상블 기법을 적용한 분류 모델을 학습시키고 테스트 세트에 대한 정확도를 출력하였습니다.
가중치 벡터를 w라 하고, L1 규제 계수를 λ라고 할 때, L1 규제 손실 함수는 다음과 같이 정의됩니다.
L1(w) = λ * ||w||_1
여기서 ||w||_1은 w의 L1 노름을 나타내며, 다음과 같이 정의됩니다.
||w||_1 = Σ_i |w_i|
λ는 하이퍼파라미터로서, L1 규제의 정도를 조절합니다. λ가 크면 규제가 강해져 가중치가 더 많이 감소하고, λ가 작으면 규제가 약해져 가중치에 덜 영향을 미칩니다.
L1 규제가 적용된 최종 손실 함수는 기존 손실 함수인 L(w)와 L1 규제 손실 함수인 L1(w)를 합한 형태로 정의됩니다.
Total_Loss(w) = L(w) + L1(w)
L1 규제는 가중치 벡터의 일부 요소를 0으로 만들어 스파스한 모델을 만듭니다. 이 특징은 특성 선택(feature selection) 효과를 가져와서 불필요한 특성의 가중치를 0으로 만들어 모델의 복잡도를 줄이고 일반화 성능을 향상시킵니다. 이러한 이유로 L1 규제는 희소한 가중치 벡터를 생성하고자 할 때 유용하게 사용됩니다.
L1 규제는 가중치 벡터의 L1 노름(절대값의 합)을 손실 함수에 추가하는 것으로, 모델의 가중치를 제한하여 오버피팅을 줄이는 방법입니다. L1 규제는 몇몇 가중치를 0으로 만들어 스파스한 모델을 만듭니다. 이는 모델의 일반화를 향상시키며, 특성 선택(feature selection) 효과도 가집니다.
아래 코드는 L1 규제를 포함하는 손실 함수를 작성하는 예입니다.
# 손실 함수와 함께 사용되는 L1 규제를 계산하는 함수
def l1_regularizer(model, lambda_l1):
l1_loss = 0.0
for param in model.parameters():
l1_loss += torch.sum(torch.abs(param))
return lambda_l1 * l1_loss
# 하이퍼파라미터 설정
lambda_l1 = 0.001
# 모델 생성
model = MyModel(input_dim, hidden_dim, output_dim)
# 손실 함수 (예: 크로스 엔트로피)
criterion = nn.CrossEntropyLoss()
# 옵티마이저 생성
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
# 학습 루프
for epoch in range(num_epochs):
for data, target in dataloader:
# 예측 및 손실 계산
output = model(data)
loss = criterion(output, target)
# L1 규제 추가
loss += l1_regularizer(model, lambda_l1)
# 역전파 및 가중치 업데이트
optimizer.zero_grad()
loss.backward()
optimizer.step()
위의 예제에서, l1_regularizer 함수는 모델의 모든 가중치에 대한 절대값의 합을 계산하여 L1 손실을 반환합니다. 이 L1 손실은 기존의 손실 함수에 더해져 최종 손실을 구성하게 됩니다. 이렇게 손실 함수에 L1 규제를 추가함으로써 모델의 가중치를 제한하고 일반화를 향상 시킬 수 있습니다.
딥러닝에서 정규화는 오버피팅을 방지하고 일반화 성능을 향상시키는 데 사용되는 기술입니다. 오버피팅은 모델이 학습 데이터에 지나치게 적응하여 새로운 데이터에 대한 예측 성능이 저하되는 현상입니다. 정규화 기법을 사용하여 모델의 복잡도를 제한하고 훈련 과정을 안정화시킬 수 있습니다.
딥러닝에서 사용되는 주요 정규화 기법은 다음과 같습니다.
1. 가중치 감쇠 (Weight Decay): 가중치 감쇠는 손실 함수에 가중치에 대한 L2 노름을 추가하여 모델의 가중치를 작게 유지하는 것을 목표로 합니다. 작은 가중치 값은 모델의 복잡도를 낮추고 오버피팅을 방지할 수 있습니다. 파이토치에서는 옵티마이저의 weight_decay 매개변수를 사용하여 가중치 감쇠를 적용할 수 있습니다.
2. 드롭아웃 (Dropout): 드롭아웃은 학습 과정에서 무작위로 일부 뉴런을 비활성화시켜 가중치의 공동 의존성을 감소시키는 방법입니다. 드롭아웃은 앙상블 학습의 효과를 모방하여 일반화 성능을 향상시킵니다. 파이토치에서는 nn.Dropout 레이어를 사용하여 드롭아웃을 적용할 수 있습니다.
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 드롭아웃 레이어 추가 (확률 0.5)
self.dropout = nn.Dropout(0.5)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = torch.relu(self.fc1(x))
# 드롭아웃 적용
x = self.dropout(x)
return self.fc2(x)
3. 배치 정규화 (Batch Normalization): 배치 정규화는 각 층의 입력 분포를 정규화하여 학습 속도를 높이고 안정화시키는 기법입니다. 배치 정규화는 미니배치의 평균과 분산을 사용하여 각 층의 입력을 정규화하고, 학습 가능한 스케일과 이동 매개변수를 도입하여 표현력을 유지합니다. 파이토치에서는 `nn.BatchNorm1d, nn.BatchNorm2d` 등의 레이어를 사용하여 배치 정규화를 적용할 수 있습니다.
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.batch_norm = nn.BatchNorm1d(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc1(x)
x = self.batch_norm(x)
x = torch.relu(x)
return self.fc2(x)
4. 레이어 정규화 (Layer Normalization): 레이어 정규화는 배치 정규화와 유사한 원리로 작동하지만, 미니배치의 차원이 아닌 특성 차원에서 정규화를 수행합니다. 이로 인해 미니배치의 크기에 영향을 받지 않으며, 순환 신경망과 같은 동적인 구조에서도 사용할 수 있습니다. 파이토치에서는 nn.LayerNorm 레이어를 사용하여 레이어 정규화를 적용할 수 있습니다.
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.layer_norm = nn.LayerNorm(hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc1(x)
x = self.layer_norm(x)
x = torch.relu(x)
return self.fc2(x)
5. 가중치 초기화 (Weight Initialization):가중치 초기화는 모델의 가중치를 적절한 값으로 설정하여 학습 속도를 개선하고 안정화시키는 방법입니다. 적절한 가중치 초기화 기법을 사용하면 학습 중 발산이나 소실 문제를 예방할 수 있습니다. 파이토치에서는 torch.nn.init 모듈을 사용하여 다양한 가중치 초기화 기법을 적용할 수 있습니다. 예를 들어, Xavier 초기화와 He 초기화는 각각 활성화 함수가 없거나 ReLU 계열일 때 사용되는 방법입니다.
def weights_init(m):
if isinstance(m, nn.Linear):
nn.init.xavier_uniform_(m.weight)
nn.init.zeros_(m.bias)
model = MyModel(input_dim, hidden_dim, output_dim)
model.apply(weights_init)
정규화 기법은 딥러닝 모델의 일반화 성능을 향상시키기 위한 중요한 요소입니다. 다양한 정규화 기법을 적절히 조합하여 사용하면 오버피팅을 방지하고 모델의 학습 속도와 안정성을 개선할 수 있습니다. 또한, 정규화 기법은 모델의 구조나 데이터셋에 따라 적용 방법이나 효과가 달라질 수 있으므로, 실험을 통해 가장 적합한 정규화 전략을 찾아야 합니다.
6. 그룹 정규화 (Group Normalization): 그룹 정규화는 배치 정규화와 레이어 정규화의 중간 형태로 볼 수 있습니다. 이 방법은 채널을 그룹으로 나누고 각 그룹에서 정규화를 수행합니다. 그룹 정규화는 작은 배치 크기에 대해서도 안정적인 성능을 보이며, 레이어와 배치 정규화의 장점을 모두 활용할 수 있는 방법입니다. 파이토치에서는 nn.GroupNorm 레이어를 사용하여 그룹 정규화를 적용할 수 있습니다.
class MyModel(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim):
super(MyModel, self).__init__()
self.fc1 = nn.Linear(input_dim, hidden_dim)
self.group_norm = nn.GroupNorm(num_groups=4, num_channels=hidden_dim)
self.fc2 = nn.Linear(hidden_dim, output_dim)
def forward(self, x):
x = self.fc1(x)
x = self.group_norm(x)
x = torch.relu(x)
return self.fc2(x)
7. Spectral Normalization (스펙트럴 정규화):스펙트럴 정규화는 가중치 행렬의 스펙트럼(특잇값)을 조절하여 학습 과정을 안정화시키는 기법입니다. 이 방법은 주로 생성적 적대 신경망(GAN)에서 사용되며, 모델의 가중치 행렬에서 가장 큰 특잇값을 제한함으로써 학습 동안의 발산 문제를 완화할 수 있습니다. 파이토치에서는 nn.utils.spectral_norm을 사용하여 스펙트럴 정규화를 적용할 수 있습니다.
이처럼 딥러닝에서 정규화 기법은 다양한 형태로 존재하며, 각각의 기법은 모델의 일반화 성능을 향상시키고 학습 과정을 안정화하는 데 도움을 줍니다. 따라서, 모델의 성능을 최적화하고 싶다면 여러 정규화 기법을 실험적으로 적용해보고 그 결과를 비교하는 것이 중요합니다. 최적의 정규화 전략은 모델 구조, 데이터셋, 학습 목표 등에 따라 달라질 수 있으므로, 여러 가지 방법을 적절하게 조합하여 사용하는 것이 좋습니다.
또한, 정규화 기법은 모델의 복잡도나 학습 알고리즘에 직접적인 영향을 미칠 수 있으므로, 정규화 방법을 변경할 때마다 하이퍼파라미터를 재조정하는 것이 중요합니다. 예를 들어, 배치 정규화를 적용한 모델은 학습률을 더 높게 설정할 수 있으며, 가중치 감쇠를 사용할 때는 L2 규제 계수를 조절해야 할 수도 있습니다.
마지막으로, 정규화 기법은 모델이 새로운 데이터에 대해 좀 더 민감하게 반응할 수 있도록 도와주지만, 오버피팅을 완전히 제거할 수는 없습니다. 따라서, 데이터의 품질과 양을 높이는 것도 중요하며, 교차 검증과 같은 모델 검증 기법을 사용하여 모델의 일반화 성능을 평가하는 것이 좋습니다. 이를 통해 더욱 견고하고 성능이 좋은 딥러닝 모델을 구축할 수 있습니다.
베이지안 딥러닝은 딥러닝과 베이지안 추론을 결합한 방법입니다. 베이지안 추론은 데이터와 모델에 대한 불확실성을 수학적으로 정량화하고 추론 과정에 포함시키는 것을 목표로 합니다. 베이지안 딥러닝은 신경망의 가중치에 대한 확률 분포를 추정하여, 모델의 예측 불확실성을 계산하는 데 사용합니다.
베이지안 딥러닝의 핵심 개념은 다음과 같습니다:
1. 사전 분포 (Prior Distribution): 가중치에 대한 사전 지식을 표현하는 확률 분포입니다. 사전 분포는 통상적으로 정규 분포와 같은 균형 잡힌 분포로 설정됩니다.
2. 가능도 함수 (Likelihood Function): 관측된 데이터와 가중치 사이의 관계를 나타내는 함수입니다. 딥러닝에서 가능도 함수는 일반적으로 손실 함수의 역수로 생각할 수 있습니다.
3. 사후 분포 (Posterior Distribution): 사전 분포와 가능도 함수를 결합하여 계산한 가중치에 대한 확률 분포입니다. 이 분포는 베이즈 정리를 통해 구할 수 있습니다.
베이즈 정리는 다음과 같이 표현됩니다:
P(θ|D) = P(D|θ) * P(θ) / P(D)
여기서 θ는 모델 가중치, D는 데이터, P(θ)는 사전 분포, P(D|θ)는 가능도 함수, P(θ|D)는 사후 분포입니다.
변분 추론 (Variational Inference): 사후 분포를 근사하는 확률 분포를 선택하고, 그 사이의 차이를 최소화하는 방식입니다. 이 방법에서는 Kullback-Leibler 발산(KL divergence)을 사용하여 두 분포 간의 차이를 측정합니다.
Markov Chain Monte Carlo (MCMC): 사후 분포를 근사하는 샘플을 생성하는 데 사용되는 확률론적 알고리즘입니다. 대표적인 MCMC 방법인 해밀턴 몬테카를로(Hamiltonian Monte Carlo, HMC)는 해밀턴 방정식을 사용하여 효율적으로 사후 분포를 탐색합니다.
베이지안 딥러닝은 다음과 같은 장점을 가지고 있습니다:
1. 불확실성 추정: 모델의 가중치에 대한 확률 분포를 추정함으로써, 예측 결과의 불확실성을 계산할 수 있습니다. 이를 통해 모델이 확신하지 못하는 영역에 대한 예측에 대한 신뢰도를 낮출 수 있습니다.
2. 오버피팅 방지: 가중치에 대한 사후 분포를 사용하면, 데이터에 너무 맞추지 않고 일반화를 유지할 수 있습니다. 이를 통해 오버피팅을 방지할 수 있습니다.
3. 데이터 효율성 향상: 베이지안 딥러닝은 불확실성을 고려하기 때문에, 데이터가 적은 상황에서도 상대적으로 안정적인 결과를 얻을 수 있습니다.
4. 베이지안 딥러닝을 파이토치로 구현하는 예시는 다음과 같습니다. 이 예시에서는 변분 오토인코더(Variational Autoencoder, VAE)를 사용합니다.
import torch
import torch.nn as nn
import torch.optim as optim
#인코더 정의
class Encoder(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(Encoder, self).__init__()
# 입력층과 은닉층 연결
self.fc1 = nn.Linear(input_dim, hidden_dim)
# 은닉층과 잠재변수 평균 연결
self.fc21 = nn.Linear(hidden_dim, latent_dim)
# 은닉층과 잠재변수 로그 분산 연결
self.fc22 = nn.Linear(hidden_dim, latent_dim)
def forward(self, x):
# 활성화 함수로 ReLU를 사용하여 은닉층 계산
h1 = torch.relu(self.fc1(x))
# 잠재변수의 평균과 로그 분산 반환
return self.fc21(h1), self.fc22(h1)
# 디코더 정의
class Decoder(nn.Module):
def __init__(self, latent_dim, hidden_dim, output_dim):
super(Decoder, self).__init__()
# 잠재변수와 은닉층 연결
self.fc3 = nn.Linear(latent_dim, hidden_dim)
# 은닉층과 출력층 연결
self.fc4 = nn.Linear(hidden_dim, output_dim)
def forward(self, z):
# 활성화 함수로 ReLU를 사용하여 은닉층 계산
h3 = torch.relu(self.fc3(z))
# 활성화 함수로 시그모이드를 사용하여 출력층 계산
return torch.sigmoid(self.fc4(h3))
# VAE 전체 정의
class VAE(nn.Module):
def __init__(self, input_dim, hidden_dim, latent_dim):
super(VAE, self).__init__()
# 인코더와 디코더 객체 생성
self.encoder = Encoder(input_dim, hidden_dim, latent_dim)
self.decoder = Decoder(latent_dim, hidden_dim, input_dim)
#재매개변수화 기법을 사용하여 샘플링
def reparameterize(self, mu, logvar):
std = torch.exp(0.5 * logvar)
eps = torch.randn_like(std)
return mu + eps * std
def forward(self, x):
# 인코더를 통해 입력 데이터의 잠재변수 평균과 로그 분산 계산
mu, logvar = self.encoder(x)
# 재매개변수화 기법을 사용하여 샘플링
z = self.reparameterize(mu, logvar)
# 디코더를 통해 재구성된 출력 계산
return self.decoder(z), mu, logvar
이 예시에서는 변분 오토인코더를 구현하였습니다. 이제 학습과 손실 함수를 정의하고 VAE를 학습시킬 수 있습니다.
def vae_loss(recon_x, x, mu, logvar):
# 재구성 손실: 원본데이터와 재구성된 데이터 간의 차이를 계산(이진 크로스 엔트로피 사용)
recon_loss = nn.BCELoss(reduction='sum')(recon_x, x)
#KL 발산: 잠재 변수의 사전 분포와 근사된 사후 분포 간의 차이를 계산
kl_divergence = -0.5 * torch.sum(1 + logvar - mu.pow(2) - logvar.exp())
# 전체 손실은 재구성 손실과 KL 발산의 합
return recon_loss + kl_divergence
# 하이퍼파라미터 설정
input_dim = 784
hidden_dim = 400
latent_dim = 20
learning_rate = 0.001
epochs = 20
#VAE 모델 생성
vae = VAE(input_dim, hidden_dim, latent_dim)
#옵티마이저 설정(Adam 사용)
optimizer = optim.Adam(vae.parameters(), lr=learning_rate)
#학습 루프
for epoch in range(epochs):
for batch_idx, (data, _) in enumerate(train_loader):
#기울기 초기화
optimizer.zero_grad()
# 모델에 데이터를 전달하고 재구성된 데이터, 잠재 변수의 평균, 로그 분산 계산
recon_batch, mu, logvar = vae(data)
# 손실 함수 계산
loss = vae_loss(recon_batch, data, mu, logvar)
# 역전파를 통해 기울기 계산
loss.backward()
# 옵티마이저를 통해 가중치 업데이트
optimizer.step()
변분 오토인코더는 베이지안 딥러닝의 한 예입니다. 비슷한 방식으로 다른 딥러닝 모델에 베이지안 추론을 적용할 수도 있습니다. 예를 들어, torch.nn.Module의 서브클래스로 베이지안 신경망을 정의하고 변분 추론을 사용하여 가중치의 사후 분포를 근사할 수 있습니다. 이를 통해 예측의 불확실성을 계산하고 모델을 안정적으로 학습시킬 수 있습니다.
베이지안 딥러닝은 불확실성 추정과 일반화 성능 향상을 위해 많은 연구가 진행되고 있는 분야입니다. 다양한 베이지안 딥러닝 모델과 근사 추론 방법이 연구되고 있으며, 이를 통해 딥러닝의 한계를 극복하려는 시도가 이루어지고 있습니다.
딥러닝 모델의 학습에서는 최적화 알고리즘이 매우 중요한 역할을 합니다. 최적화 알고리즘은 모델의 파라미터 값을 조정하여 손실 함수(loss function) 값을 최소화하는 것이 목적입니다. 이번에는 대표적인 최적화 알고리즘 몇 가지에 대해 자세히 설명해드리겠습니다.
1. 확률적 경사 하강법(Stochastic Gradient Descent, SGD)
확률적 경사 하강법은 가장 기본적인 최적화 알고리즘 중 하나로, 모든 데이터 샘플을 사용하지 않고 일부 샘플을 사용하여 계산합니다. 이를 통해 계산 속도를 높이고, 메모리 사용량을 줄일 수 있습니다. SGD는 각 파라미터에 대한 그래디언트(기울기)를 계산하고, 파라미터를 그래디언트 반대 방향으로 이동시켜 손실 함수 값을 줄입니다.
SGD는 각 파라미터에 대한 그래디언트(기울기)를 계산하고, 파라미터를 그래디언트 반대 방향으로 이동시켜 손실 함수 값을 줄입니다. 이 과정에서 파라미터를 업데이트할 때, 학습률(learning rate)이라는 하이퍼파라미터를 사용합니다. 학습률은 파라미터를 얼마나 크게 이동시킬지 결정하는데, 학습률이 크면 빠르게 수렴할 수 있지만, 최적점을 지나쳐 발산할 수 있고, 학습률이 작으면 최적점에 수렴하는 데 시간이 오래 걸립니다.
SGD의 동작 방식은 다음과 같습니다.
데이터에서 임의로 하나의 샘플을 선택합니다.
선택된 샘플을 모델에 입력하고, 출력을 계산합니다.
선택된 샘플에 대한 손실 함수 값을 계산합니다.
손실 함수의 그래디언트(기울기)를 계산합니다.
그래디언트 반대 방향으로 파라미터를 이동시킵니다.
위 과정을 반복합니다.
확률적 경사 하강법(Stochastic Gradient Descent, SGD)은 기계 학습에서 매개 변수를 최적화하는데 사용되는 반복적인 최적화 알고리즘이다. 일반적인 경사 하강법과 달리, 확률적 경사 하강법은 각 반복에서 하나의 데이터 포인트를 임의로 선택하여 경사를 계산한다. 이렇게 하면 계산 속도가 빨라지고, 더 빈번한 업데이트를 통해 최적화에 도달할 수 있다.
수학적 모델로 표현하면 다음과 같다:
목적 함수 (비용 함수) J(θ)를 최소화하고자 한다. 여기서 θ는 모델의 매개 변수이다.
N은 데이터 포인트의 수, L은 손실 함수, (x^(i), y^(i))는 i번째 데이터 포인트 (입력, 출력)이다.
각 반복에서, 데이터 포인트 (x^(i), y^(i)) 중에서 하나를 무작위로 선택한다.
선택된 데이터 포인트에 대해 경사(그레디언트)를 계산한다.
∇J(θ) ≈ ∇L(y^(i), f(x^(i), θ))
매개 변수 θ를 업데이트한다.
θ = θ - α * ∇J(θ)
여기서 α는 학습률(learning rate)로, 얼마나 빨리 최적화에 도달할지를 결정하는 하이퍼파라미터다.
수렴 기준을 충족하거나 최대 반복 횟수에 도달할 때까지 2-4단계를 반복한다.
이러한 방식으로, 확률적 경사 하강법은 전체 데이터셋의 경사를 한 번에 계산하는 것이 아니라, 하나의 데이터 포인트를 사용하여 근사치를 계산하여 최적화를 빠르게 수행한다. 이로 인해 속도가 빨라지지만, 확률적 경사 하강법의 수렴은 일반적인 경사 하강법보다 더 불안정하다는 단점이 있다. 이를 극복하기 위해 여러 가지 변형이 제안되었다.
import torch
import torch.nn as nn
import torch.optim as optim
# 데이터 준비
x = torch.tensor([[1.0], [2.0], [3.0], [4.0]])
y = torch.tensor([[2.0], [4.0], [6.0], [8.0]])
# 모델 정의
class LinearRegression(nn.Module):
def __init__(self):
super(LinearRegression, self).__init__()
self.linear = nn.Linear(1, 1)
def forward(self, x):
return self.linear(x)
model = LinearRegression()
# 손실 함수
criterion = nn.MSELoss()
# 하이퍼 파라미터
learning_rate = 0.01
epochs = 1000
확률적 경사 하강법(Stochastic Gradient Descent, SGD)의 불안정한 수렴 특성을 개선하기 위해 여러 가지 변형이 제안되었습니다. 이러한 변형들은 주로 학습률 조정, 모멘텀 사용, 그리고 미니 배치를 사용하는 것입니다. 여기 일부 주요 변형에 대해 설명하겠습니다.
<SGD 소스>
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
for i in range(x.size(0)):
inputs = x[i]
targets = y[i]
# 경사 초기화
optimizer.zero_grad()
# 순전파
outputs = model(inputs)
# 손실 계산
loss = criterion(outputs, targets)
# 역전파
loss.backward()
# 매개변수 업데이트
optimizer.step()
1-1. Mini-Batch Gradient Descent (미니 배치 경사 하강법):
미니 배치 경사 하강법은 SGD와 일반 경사 하강법의 절충안입니다. 이 방법에서는 한 번의 반복에서 전체 데이터셋을 사용하는 것이 아니라, 데이터셋의 작은 무작위 부분집합(미니 배치)을 사용하여 경사를 계산합니다. 이렇게 하면 계산 효율성과 수렴 속도 사이에 균형을 이룰 수 있습니다.
batch_size = 2
optimizer = optim.SGD(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
for i in range(0, x.size(0), batch_size):
inputs = x[i:i+batch_size]
targets = y[i:i+batch_size]
optimizer.zero_grad()
outputs = model(inputs)
loss = criterion(outputs, targets)
loss.backward()
optimizer.step()
1-2. Momentum (모멘텀):
모멘텀은SGD의 변형 알고리즘으로,이전 그래디언트를 고려하여 파라미터 값을 업데이트합니다.이전 그래디언트와 현재 그래디언트를 일정 비율로 조합하여 이전 그래디언트 방향과 현재 그래디언트 방향을 모두 고려하여 파라미터 값을 업데이트합니다.이를 통해SGD보다 더 빠르게 수렴할 수 있습니다.
모멘텀은 경사 하강법에 관성 개념을 도입하여 최적화를 개선합니다. 이전 반복에서의 경사를 고려하여 매개 변수를 업데이트하는 방식입니다. 이를 통해 수렴 속도가 빨라지고, 지역 최소값(local minima)에서 벗어나는 데 도움이 됩니다.
θ = θ - α * ∇J(θ) + β * v_t
v_t는 t-1 시점에서의 경사에 대한 가중치입니다. β는 모멘텀 계수로 0과 1 사이의 값입니다.
momentum = 0.9
optimizer = optim.SGD(model.parameters(), lr=learning_rate, momentum=momentum)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-3. Adagrad (Adaptive Gradient Algorithm):
아다그라드는 학습률을 각각의 파라미터에 대해 동적으로 조정하여 파라미터를 업데이트합니다.이전 그래디언트의 크기가 큰 파라미터는 학습률을 작게 조정하고,이전 그래디언트의 크기가 작은 파라미터는 학습률을 크게 조정합니다.이를 통해SGD와 모멘텀보다 더 빠르게 수렴할 수 있습니다.
Adagrad는 학습률을 매개 변수별로 독립적으로 조정하는 방법입니다. 이는 각 매개 변수에 대한 그래디언트의 제곱 누적을 사용하여 학습률을 조정합니다. 이 방법은 희소한 데이터에 대해 더 나은 결과를 가져오며, 수렴 속도를 개선합니다.
θ = θ - (α / √(G + ε)) * ∇J(θ)
G는 각 매개 변수에 대한 그래디언트의 제곱 누적이며, ε는 0으로 나누는 것을 방지하기 위한 작은 상수입니다.
optimizer = optim.Adagrad(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-4. RMSprop (Root Mean Square Propagation):
RMSProp은 아다그라드와 유사한 알고리즘으로,그래디언트 제곱 평균을 사용하여 학습률을 동적으로 조정합니다.그러나 아다그라드와 달리,모든 이전 그래디언트를 누적하는 대신,최근 그래디언트에 더 많은 가중치를 부여합니다.이를 통해SGD보다 더 빠르게 수렴할 수 있습니다.
RMSprop는 Adagrad의 학습률 감소 문제를 해결하기 위해 제안되었습니다. 이 방법은 최근 반복에서 계산된 그래디언트의 제곱 평균을 사용하여 학습률을 조정합니다.
θ = θ - (α / √(E[g^2] + ε)) * ∇J(θ)
E[g^2]는 최근 반복에서의 그래디언트의 제곱 평균을 나타냅니다. 이는 지수 가중 평균(exponentially weighted average)을 사용하여 계산됩니다.
optimizer = optim.RMSprop(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-5. Adam (Adaptive Moment Estimation):
아담은 모멘텀과 아다그라드를 합친 알고리즘으로,그래디언트와 그래디언트 제곱을 각각 모멘텀과 아다그라드처럼 사용하여 파라미터 값을 업데이트합니다.또한,학습률도 각각의 파라미터에 대해 동적으로 조정합니다.이를 통해SGD,모멘텀,아다그라드보다 더 빠르고 안정적으로 수렴할 수 있습니다.
Adam은 모멘텀과 RMSprop의 아이디어를 결합한 최적화 알고리즘입니다. Adam은 각 매개 변수에 대해 일차 모멘트 추정(모멘텀)과 이차 모멘트 추정(RMSprop)을 유지하고, 이를 사용하여 학습률을 동적으로 조정합니다.
m_t = β1 * m_t-1 + (1 - β1) * ∇J(θ)
v_t = β2 * v_t-1 + (1 - β2) * (∇J(θ))^2
m_t_hat = m_t / (1 - β1^t)
v_t_hat = v_t / (1 - β2^t)
θ = θ - α * (m_t_hat / (√v_t_hat + ε))
여기서 m_t와 v_t는 각각 일차 및 이차 모멘트 추정값입니다. β1과 β2는 각각 일차 및 이차 모멘트에 대한 감쇠 계수이며, ε은 0으로 나누는 것을 방지하기 위한 작은 상수입니다. t는 현재 반복 횟수를 나타냅니다.
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-6. AdaMax:
AdaMax는 Adam 알고리즘의 확장으로, 그래디언트의 무한 노름(infinity norm)을 사용하여 업데이트를 조정합니다. 이 방법은 무한 노름을 사용하기 때문에 Adam보다 더 강인하다고 알려져 있습니다.
이러한 변형 중 일부는 다른 상황이나 문제에 대해 더 나은 성능을 보일 수 있습니다. 따라서 실제로는 문제에 따라 가장 적합한 최적화 알고리즘을 선택하는 것이 중요합니다. 이를 위해 교차 검증(cross-validation)과 같은 기법을 사용하여 여러 알고리즘의 성능을 비교해 볼 수 있습니다.
optimizer = optim.Adamax(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-7. Adadelta
Adadelta는 RMSProp의 변형 알고리즘으로, 학습률을 동적으로 조정하는 대신 그래디언트 제곱 평균과 파라미터 업데이트 값의 제곱 평균을 사용합니다. 이전 업데이트 값의 제곱 평균도 함께 사용하여 파라미터를 업데이트합니다. 이를 통해 학습률을 더욱 자동으로 조정하고, RMSProp보다 더 빠르게 수렴할 수 있습니다.
Adadelta는 Adagrad의 학습률 감소 문제를 해결하기 위해 제안되었습니다. Adadelta는 최근 반복에서 계산된 그래디언트의 제곱 평균과 이전 반복에서의 매개변수 업데이트의 제곱 평균을 사용하여 학습률을 조정합니다.
optimizer = optim.Adadelta(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-8. AdamW
AdamW는 아담의 변형 알고리즘으로, 가중치 감쇠(weight decay)를 추가하여 학습률을 조정합니다. 가중치 감쇠는 모델의 복잡도를 줄이기 위해 가중치 값이 작아지도록 하는 역할을 합니다. 이를 통해 아담보다 더 안정적으로 수렴할 수 있습니다.
weight_decay = 0.01
optimizer = optim.AdamW(model.parameters(), lr=learning_rate, weight_decay=weight_decay)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-9. AdamP
AdamP는 Adam의 변형 알고리즘 중 하나로, L2 정규화 항에 대한 학습률을 동적으로 조정합니다. 기존의 Adam은 L2 정규화 항에 대해 학습률을 고정시켜 사용하는 반면, AdamP는 L2 정규화 항의 크기에 따라 학습률을 동적으로 조절합니다. 이를 통해 더욱 안정적인 최적화를 이룰 수 있습니다.
AdamP는 적응형 페널티를 도입하여 계층별로 학습률을 조절하는 최적화 알고리즘입니다. 이 최적화기는 adamp 라이브러리를 설치하여 사용할 수 있습니다.
>> pip install adamp ## 설치 필요
from adamp import AdamP
optimizer = AdamP(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-10. AdaBelief
AdaBelief는 그래디언트와 이전 그래디언트의 변화율을 고려한 학습률 동적 조절 방식을 사용합니다. 이전 그래디언트 방향의 변화량이 크면 학습률을 감소시키고, 변화량이 작으면 학습률을 증가시킵니다. 또한, 두 그래디언트의 표준 편차 비율을 사용하여 이상치(outlier)를 제거합니다. 이를 통해 Adam보다 더욱 안정적인 최적화를 이룰 수 있습니다.
from adabelief_pytorch import AdaBelief
optimizer = AdaBelief(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
1-11. RAdam
RAdam은 그래디언트의 분산에 대한 편향 보정(bias correction)을 수행하는 Adam의 변형 알고리즘입니다. 기존의 Adam은 처음에는 그래디언트가 적을 때 학습률을 크게 하고, 이후에는 그래디언트가 커질수록 학습률을 작게 조절합니다. 그러나 이 방식은 초기에 그래디언트가 적을 때, 파라미터의 큰 흔들림(shaking) 현상이 발생할 수 있습니다. RAdam은 이러한 현상을 막기 위해, 초기에 그래디언트에 대한 분산을 과소추정(underestimate)한 것을 보정하는 방식을 사용합니다. 이를 통해 Adam보다 더욱 안정적인 최적화를 이룰 수 있습니다.
from radam import RAdam
optimizer = RAdam(model.parameters(), lr=learning_rate)
for epoch in range(epochs):
optimizer.zero_grad()
outputs = model(x)
loss = criterion(outputs, y)
loss.backward()
optimizer.step()
이러한 최적화 알고리즘은 다양한 딥러닝 문제에 적용할 수 있으며, 각 알고리즘이 특정 문제에 대해 얼마나 잘 작동하는지는 문제에 따라 달라집니다. 따라서 여러 알고리즘을 실험하고 문제에 가장 적합한 최적화 알고리즘을 선택하는 것이 중요합니다.
딥러닝에서 손실 함수(loss function)는 모델의 출력과 실제값 사이의 오차를 측정하는 함수입니다. 모델이 예측한 값과 실제 값이 일치하면 손실 함수의 값은 작아지며, 이 오차를 최소화하는 것이 딥러닝의 목표 중 하나입니다. 손실 함수는 모델이 학습하는 동안 사용되며, 모델의 가중치(weight)를 업데이트하는 데 사용됩니다.
딥러닝에서 사용되는 대표적인 손실 함수에는 다음과 같은 것들이 있습니다.
Mean Squared Error(MSE)
MSE는 예측값과 실제값 사이의 평균 제곱 오차를 계산합니다. 실제값과 예측값의 차이를 제곱하여 평균을 구한 값입니다.
SVM(Support Vector Machine)에서 사용되는 손실 함수입니다. SVM은 선형 분류 모델로서 Hinge Loss는 실제값과 예측값 사이의 차이가 일정 이상인 경우에만 오차를 계산합니다. 차이가 작으면 오차를 계산하지 않으므로 모델이 조금씩 틀리는 경우에는 학습이 더 원활해지게 됩니다.
Hinge Loss 공식
여기서, y는 실제값, y^는 예측값, n은 샘플의 개수입니다. 이 손실 함수는 SVM에서 주로 사용됩니다.
데이터 분포는 데이터 포인트들이 어떻게 퍼져 있는지를 나타내는 특성입니다. 데이터 분포를 이해하는 것은 데이터를 전처리하거나, 모델을 선택하고 튜닝하는데 도움이 됩니다. 몇 가지 일반적인 데이터 분포에 대한 설명과 이를 시각화하는 Python 예제 코드를 제공하겠습니다.
균일 분포 (Uniform Distribution):
균일 분포는 모든 값이 동일한 확률로 발생하는 분포입니다. 이러한 분포에서 데이터 포인트는 구간 내에서 균등하게 분포되어 있습니다.
균일 분포(Uniform Distribution)는 확률 및 통계학에서 모든 값이 동일한 확률로 발생하는 연속 확률 분포입니다. 균일 분포는 특정 구간 내의 모든 값이 동일한 확률 밀도를 가지기 때문에, 이 구간 내에서 데이터 포인트는 균등하게 분포되어 있다고 할 수 있습니다.
균일 분포는 다음 두 가지 파라미터로 정의됩니다.
a: 분포의 최솟값 (구간의 시작점)
b: 분포의 최댓값 (구간의 끝점)
이 때, a와 b 사이의 모든 값은 동일한 확률 밀도를 갖습니다. 확률 밀도 함수(probability density function, PDF)는 다음과 같이 표현됩니다:
f(x) = { 1 / (b - a) if a <= x <= b,
0 otherwise.
누적 분포 함수(cumulative distribution function, CDF)는 다음과 같이 표현됩니다:
F(x) = { 0 if x < a,
(x - a) / (b - a) if a <= x <= b,
1 if x > b.
균일 분포는 임의의 실험에서 모든 결과가 동일한 확률로 발생할 때 사용할 수 있습니다. 예를 들어, 공정한 주사위를 던지는 경우 또는 룰렛 휠을 돌리는 경우와 같이 각 결과가 동일한 확률로 발생하는 상황에서 균일 분포를 사용할 수 있습니다. 이와 같은 경우에 균일 분포는 데이터의 특성을 잘 나타낼 수 있으며, 이를 통해 모델링 및 분석 작업을 수행할 수 있습니다.
import numpy as np
import matplotlib.pyplot as plt
# 균일 분포 생성
uniform_data = np.random.uniform(-10, 10, 1000)
# 히스토그램 시각화
plt.hist(uniform_data, bins=30, density=True)
plt.title('Uniform Distribution')
plt.show()
정규 분포 (Normal Distribution):
정규 분포(Normal Distribution), 또는 가우시안 분포(Gaussian Distribution)는 확률 이론과 통계학에서 가장 널리 사용되는 연속 확률 분포입니다. 정규 분포는 평균(μ) 주변에서 대칭인 종 모양(bell-shaped)의 분포를 가지며, 이 분포의 두께는 표준 편차(σ)에 의해 결정됩니다.
정규 분포의 확률 밀도 함수(Probability Density Function, PDF)는 다음과 같이 표현됩니다:
정규 분포는 다양한 자연 현상과 사회 현상에서 나타나는 데이터를 설명하는 데 사용됩니다. 이는 중심극한정리(Central Limit Theorem)에 따라, 독립적이고 동일한 분포를 따르는 많은 확률 변수들의 합은 정규 분포에 가까워지기 때문입니다.
정규 분포의 몇 가지 중요한 특징은 다음과 같습니다.
대칭성: 정규 분포는 평균을 중심으로 완벽한 대칭을 이룹니다. 이는 평균에서 멀어질수록 데이터 포인트의 발생 확률이 감소한다는 것을 의미합니다.
평균, 중앙값, 최빈값이 같음: 정규 분포에서 평균, 중앙값, 최빈값이 모두 같은 위치에 있습니다.
68-95-99.7 규칙: 정규 분포에서 약 68%의 데이터가 평균 ±1σ 내에, 약 95%의 데이터가 평균 ±2σ 내에, 약 99.7%의 데이터가 평균 ±3σ 내에 위치합니다.
정규 분포는 다양한 분야에서 데이터 분석, 모델링, 추론 등에 활용됩니다. 또한, 정규성 가정을 기반으로 한 많은 통계적 검정 및 추정 방법이 개발되어 있어, 정규 분포에 대한 이해는 통계학과 확률 이론의 기초를 익히는 데 중요합니다.
정규 분포는 평균 주변으로 종 모양의 대칭 분포를 가진 데이터입니다. 대부분의 데이터 포인트가 평균에 가까이 있고, 평균에서 멀어질수록 발생 확률이 감소합니다.
# 정규 분포 생성
normal_data = np.random.normal(0, 1, 1000)
# 히스토그램 시각화
plt.hist(normal_data, bins=30, density=True)
plt.title('Normal Distribution')
plt.show()
지수 분포(Exponential Distribution)
지수 분포(Exponential Distribution)는 연속 확률 분포의 한 종류로, 어떤 사건 간의 독립적인 시간 간격이나 거리 간격을 모델링하는 데 사용됩니다. 지수 분포는 특정 사건 발생 사이의 평균 대기 시간을 나타내는 파라미터 λ(람다)를 가집니다. 람다는 사건이 평균적으로 발생하는 비율(rate)을 의미하며, 양의 실수 값입니다.
지수 분포의 확률 밀도 함수(Probability Density Function, PDF)는 다음과 같이 표현됩니다:
f(x) = { λ * exp(-λx) if x ≥ 0,
0 otherwise.
지수 분포의 누적 분포 함수(Cumulative Distribution Function, CDF)는 다음과 같이 표현됩니다:
F(x) = { 1 - exp(-λx) if x ≥ 0,
0 otherwise.
지수 분포는 다양한 분야에서 사용되며, 특히 시스템의 수명, 부품의 고장 시간, 고객 도착 간격 등을 모델링하는 데 적합합니다. 지수 분포는 메모리 없음(memoryless) 성질을 가지고 있어, 앞으로 발생할 사건의 대기 시간은 과거에 발생한 사건과 독립적입니다.
지수 분포의 몇 가지 중요한 특징은 다음과 같습니다.
단일 파라미터: 지수 분포는 단일 파라미터 λ로 완전히 정의됩니다. λ는 사건 발생의 평균 비율을 나타냅니다.
메모리 없음 성질: 과거에 발생한 사건이 앞으로 발생할 사건의 대기 시간에 영향을 미치지 않습니다.
지수 분포는 감소 함수 형태를 띠며, x 값이 증가함에 따라 확률 밀도가 감소합니다.
지수 분포를 이해하고 활용하는 것은 시스템의 수명 분석, 신뢰성 이론, 대기열 이론 등 다양한 분야에서 중요한 역할을 합니다.
지수 분포는 특정 시간 간격 또는 공간 간격 내에서 발생하는 사건의 분포를 나타냅니다. 지수 분포는 급격하게 감소하는 형태를 띠며, 데이터 포인트가 0에 가까울수록 높은 확률을 가집니다.
# 지수 분포 생성
exponential_data = np.random.exponential(1, 1000)
# 히스토그램 시각화
plt.hist(exponential_data, bins=30, density=True)
plt.title('Exponential Distribution')
plt.show()
위 예제들은 각각 균일 분포, 정규 분포, 지수 분포로부터 생성된 데이터의 히스토그램을 시각화하는 코드입니다. 이를 통해 데이터의 분포를 이해하고, 해당 분포에 적합한 모델 및 전처리 방법을 선택할 수 있습니다.
딥러닝은 인공신경망(artificial neural networks)을 사용하여 데이터에서 복잡한 패턴을 학습하는 기계학습의 한 분야입니다. 딥러닝에서 확률과 통계는 중요한 역할을 합니다. 여기서 몇 가지 주요 개념과 그들이 딥러닝에 어떻게 적용되는지를 살펴보겠습니다.
데이터 분포 (Data distribution):
데이터는 다양한 형태의 분포를 가질 수 있으며, 통계학은 이러한 분포의 특성을 이해하는 데 도움이 됩니다. 딥러닝에서도 학습 데이터의 분포를 이해하는 것이 중요합니다. 데이터 분포에 대한 이해를 통해 모델이 학습에 적합한지 평가하고, 데이터 전처리 방법을 결정할 수 있습니다.
딥러닝 모델은 손실 함수를 최소화하는 파라미터를 찾기 위해 최적화 알고리즘을 사용합니다. 확률과 통계에 기반한 최적화 알고리즘은 모델의 불확실성을 추정하고, 파라미터 공간에서 더 효과적으로 탐색할 수 있습니다. 예를 들어, 확률적 경사 하강법(Stochastic Gradient Descent, SGD)은 미니배치(mini-batch)를 사용하여 파라미터를 업데이트하며, 데이터의 확률적 샘플링을 활용합니다.
딥러닝에서 정규화는 모델이 학습 데이터에 과적합되지 않도록 조절하는 기법입니다. 정규화는 통계학에서 영감을 받았으며, 모델의 복잡성을 제한하여 일반화 능력을 향상 시킵니다. 몇 가지 정규화 기법은 다음과 같습니다:
(Sub) L1 및 L2 정규화: 이 방법은 모델의 가중치에 대한 제약을 추가하여 가중치 값이 너무 커지지 않도록 합니다. L1 정규화는 가중치의 절대값 합에 비례하는 항을 손실 함수에 추가하고, L2 정규화는 가중치의 제곱 합에 비례하는 항을 추가합니다. 이러한 정규화 기법은 모델이 학습 데이터에 과적합되는 것을 방지하고, 일반화 능력을 향상시킵니다.
(Sub) 드롭아웃 (Dropout): 드롭아웃은 학습 중에 무작위로 일부 뉴런을 비활성화시키는 방법입니다. 이를 통해 모델이 특정 뉴런에 지나치게 의존하지 않게 하여 일반화 능력을 향상시킵니다.
(Sub) 배치 정규화 (Batch normalization): 배치 정규화는 각 층의 활성화 출력을 정규화하여 학습을 안정화하고 속도를 높이는 기법입니다. 이는 모델이 더 큰 학습률을 사용할 수 있게 하여 일반화 능력을 개선합니다.
앙상블 학습은 여러 개의 모델을 결합하여 예측 성능을 향상시키는 기법입니다. 이는 통계학의 다양한 가설 검정 방법에서 영감을 받았으며, 앙상블 학습은 여러 모델의 예측 결과를 통합하여 보다 안정적이고 정확한 예측을 수행할 수 있습니다. 대표적인 앙상블 기법으로는 배깅(bagging), 부스팅(boosting), 스태킹(stacking) 등이 있습니다.
딥러닝에서 확률과 통계는 모델의 학습, 최적화, 일반화 능력 향상 및 예측 성능 향상에 필수적인 역할을 합니다. 이러한 기법들은 데이터의 특성을 이해하고, 모델의 구조와 학습 방법을 개선하여 딥러닝 모델의 성능을 최대한 높일 수 있습니다. 아래에는 확률과 통계가 딥러닝에 더욱 통합되는 방법에 대한 추가 내용이 있습니다.
활성화 함수 (Activation functions):
활성화 함수는 뉴런의 출력을 결정하는 비선형 함수입니다. 확률 및 통계 관점에서 볼 때, 시그모이드(Sigmoid)나 소프트맥스(Softmax)와 같은 활성화 함수는 확률 분포를 모델링하는 데 사용됩니다. 이러한 함수를 사용하면 출력 값의 범위를 제한하고, 모델의 예측 결과를 확률로 해석할 수 있습니다.
초기화 방법 (Initialization methods):
신경망의 가중치 초기화는 모델 학습의 성공 여부에 큰 영향을 미칩니다. 가중치 초기화 방법은 종종 확률 분포를 따르며, 예를 들어 정규 분포 또는 균등 분포를 사용할 수 있습니다. 올바른 초기화 방법을 사용하면 모델의 수렴 속도를 높이고, 학습 동안 더 나은 결과를 얻을 수 있습니다.
데이터 증강 (Data augmentation):
데이터 증강은 기존 학습 데이터를 변형하여 인공적으로 데이터셋의 크기를 확장하는 방법입니다. 확률적인 변환을 사용하여 이미지를 회전, 크기 조정, 반전 등을 통해 증강할 수 있습니다. 이를 통해 모델이 더 다양한 데이터에 적응하게 하여 일반화 능력을 향상시킬 수 있습니다.
모델 평가 및 검증 (Model evaluation and validation):
모델의 성능을 평가하고 검증하기 위해 확률과 통계 지식이 필요합니다. 예를 들어, k-겹 교차 검증(k-fold cross-validation)은 데이터를 여러 부분으로 나누어 모델의 일반화 능력을 평가하는 데 사용됩니다. 또한, 정확도(accuracy), 정밀도(precision), 재현율(recall), F1 점수 등의 평가 지표를 사용하여 모델의 성능을 정량적으로 분석할 수 있습니다.
이러한 확률 및 통계 기법들은 딥러닝 모델의 성능 향상과 일반화 능력을 향상시키는 데 큰 도움이 됩니다. 이를 통해 모델은 더욱 견고하고, 신뢰할 수 있는 결과를 제공할 수 있습니다. 또한, 이러한 기법들은 모델의 학습과정에서 발생할 수 있는 다양한 문제를 해결하는 데 도움이 됩니다.
프로바빌리스틱 프로그래밍 (Probabilistic programming):
프로바빌리스틱 프로그래밍은 확률 모델을 사용하여 불확실성을 명시적으로 다루는 프로그래밍 패러다임입니다. 이를 통해 딥러닝 모델의 구조 및 가중치에 대한 불확실성을 표현하고, 모델의 예측에 대한 신뢰도를 측정할 수 있습니다. 프로바빌리스틱 프로그래밍은 불완전한 정보를 가진 데이터셋에서 모델의 성능을 향상시킬 수 있습니다.
전이 학습 (Transfer learning):
전이 학습은 이미 학습된 모델의 일부를 새로운 문제에 적용하는 기법입니다. 통계학에서는 이를 통계적 지식 전이(statistical knowledge transfer)라고 합니다. 전이 학습을 사용하면 새로운 데이터셋에 대해 더 빠르게 학습하고, 더 나은 결과를 얻을 수 있습니다. 이는 공통적인 패턴이나 특징을 공유하는 다양한 문제 간에 지식을 전달할 수 있기 때문입니다.
요소 분석 (Factor analysis):
요소 분석은 데이터의 차원을 줄이고, 데이터의 변동성을 설명하는 잠재 요소를 찾는 통계적 기법입니다. 딥러닝에서는 요소 분석과 유사한 방법으로 특징 추출(feature extraction)을 수행할 수 있습니다. 예를 들어, 오토인코더(autoencoder)는 입력 데이터의 차원을 줄이고, 원본 데이터를 재구성하는 데 사용되는 중요한 특징을 학습합니다.
시계열 분석 (Time series analysis):
시계열 분석은 순차적으로 발생하는 데이터를 다루는 통계 기법입니다. 딥러닝에서는 순환 신경망(Recurrent Neural Networks, RNN)이나 트랜스포머(Transformer)와 같은 모델을 사용하여 시계열 데이터를 처리할 수 있습니다. 이러한 모델은 시간에 따른 패턴이나 트렌드를 학습하고, 시계열 데이터의 미래 값을 예측하는 데 사용됩니다.
확률과 통계의 기법들은 딥러닝 모델의 성능을 향상시키고, 다양한 데이터 유형 및 문제를 처리하는 데 필수적입니다. 이를 통해 모델은 더욱 견고하고 정확한 결과를 제공하며, 새로운 도메인에 적용할 수 있는 일반화 능력을 가질 수 있습니다. 이러한 기법들 또한 모델의 학습 과정에서 발생할 수 있는 문제를 해결하는데 도움이 되며, 딥러닝 연구자와 개발자들이 보다 효과적인 모델을 개발할 수 있도록 지원합니다.
또한, 확률과 통계의 기법들은 딥러닝 모델의 해석 가능성(interpretability)을 높이는 데 도움이 됩니다. 예를 들어, 학습된 가중치를 분석하거나 불확실성을 고려한 예측을 제공함으로써, 모델의 예측이 어떻게 이루어지는지 이해할 수 있습니다. 이는 모델의 결과를 신뢰할 수 있는 근거를 제공하고, 의사결정 과정에 딥러닝 모델을 보다 효과적으로 통합할 수 있습니다.
마지막으로, 확률과 통계의 기법들은 딥러닝 모델의 효율성을 높이는 데 기여할 수 있습니다. 예를 들어, 효율적인 데이터 샘플링 기법이나 데이터 증강 방법을 사용하여, 제한된 데이터셋에서도 더 나은 결과를 얻을 수 있습니다. 또한, 모델의 크기를 줄이거나 학습률을 최적화하는 등의 방법으로, 모델의 학습 속도를 높이고 리소스 사용량을 줄일 수 있습니다.
따라서 확률과 통계는 딥러닝의 핵심 구성 요소로, 다양한 측면에서 모델의 성능과 효율성을 향상시키는 데 도움이 됩니다. 이러한 지식은 딥러닝 연구자와 개발자들이 보다 강력하고 실용적인 모델을 만드는 데 필수적입니다.